Estoy en el proceso de mapear los datos abiertos de mi país y las relaciones entre ellos, y necesito hacerlo en formatos legibles por humanos y máquinas.
Estoy buscando herramientas de diagramación para la parte legible por humanos, pero necesitaría la herramienta para poder exportar los resultados a un formato legible por máquina que no sea SQL, como json o xml, para poder pasarlo a un programa de mi propia escritura para su posterior procesamiento.
Dado que no necesitaría depender de SQL, me gustaría que se admitieran tantos tipos de relaciones UML como sea posible. Sin embargo, podría arreglármelas con la asociación, la asociación reflexiva (autorreferencia) y la multiplicidad.
¿Hay alguna herramienta gratuita que pueda lograr esto?
PD: Si no es así, ¿hay bibliotecas de Python o C# que puedan leer sentencias SQL DDL en una estructura de clase?
SQL Power Architect almacena su definición como un archivo XML. Sin embargo, encuentro ese formato bastante difícil de usar, por ejemplo, XSLT.
Pero también es compatible con el formato XML de Liquibase para "ingeniería avanzada", que es más fácil de procesar que el formato que usa Power Architect (al menos en mi opinión).
Todavía estoy un poco confuso. ¿No podría usar Python para consultar la base de datos y usar ese resultado para generar XML?
Ah, "los datos abiertos de mi país, y las relaciones entre ellos". Entonces, no necesariamente todos los datos, sino las relaciones entre tablas, por ejemplo.
Si tiene acceso a los metadatos (esquema). Si lo hace, esto no debería ser difícil. Si no lo hace, ¿puede demandar consultas SQL, o está limitado a obtener datos en un formato que ellos (algún sitio web del gobierno) quieren ofrecerle?
Para aclarar: para determinar las relaciones entre los datos, su mejor enfoque es buscar claves externas .
Puede obtener esta rom del esquema de la base de datos. O, por ejemplo, ejecutando el SHOW CREATE TABLEcomando MySql.
Esta excelente respuesta muestra
Para una mesa:
SELECT
TABLE_NAME,COLUMN_NAME,CONSTRAINT_NAME, REFERENCED_TABLE_NAME,REFERENCED_COLUMN_NAME
FROM
INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE
REFERENCED_TABLE_SCHEMA = '<database>' AND
REFERENCED_TABLE_NAME = '<table>';
Para una columna:
SELECT
TABLE_NAME,COLUMN_NAME,CONSTRAINT_NAME, REFERENCED_TABLE_NAME,REFERENCED_COLUMN_NAME
FROM
INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE
REFERENCED_TABLE_SCHEMA = '<database>' AND
REFERENCED_COLUMN_NAME = '<column>';
Por supuesto, es probable que no tenga un acceso tan directo a la base de datos real, y solo una API que hace la consulta por usted.
En ese caso, veo dos posibilidades:
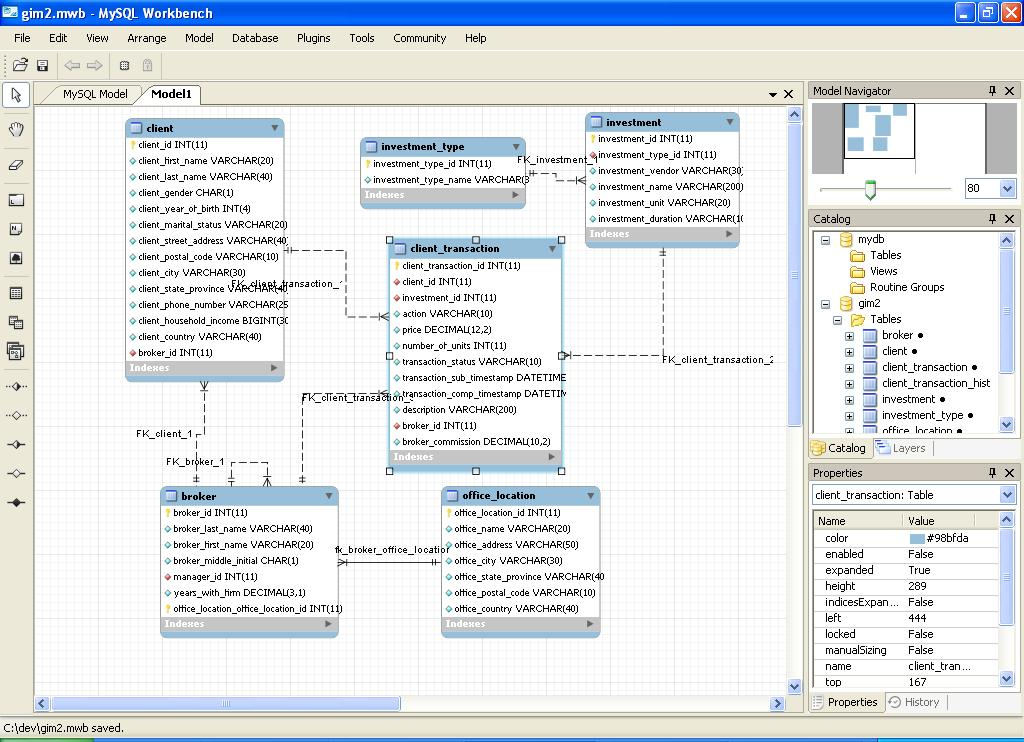
1) Contactar con quien proporciona los datos. Si lo hacen disponible gratuitamente, entonces probablemente no solo estarán dispuestos, sino realmente complacidos de ayudarlo. Si tiene mucha suerte, obtendrá acceso completo de solo lectura y podrá usar herramientas como MySql Workbench , que puede ayudarlo a aplicar ingeniería inversa a una base de datos existente y visualizarla así.
http://download.nust.na/pub6/mysql/tech-resources/articles/workbench-screenshot.png (lo siento, mi navegador se está reproduciendo y no inserta la imagen)
2) Volcar todas las mesas. No se presentará de esa manera, pero probablemente esté obteniendo el resultado de 'SELECT * From' y busque, a mano o por código, columnas con nombres idénticos.
Un buen diseño de base de datos verá columnas con nombres significativos con el mismo nombre de columna utilizado en varias columnas. Ej customer_id. order_id, etc.
Y, con un buen diseño de base de datos/buena suerte, tendrán la forma <table_name¬_Id, o <table_name>_index, o similar.
De lo cual puede suponer que customer_ides la CLAVE PRIMARIA en la customerstabla, y se usa como CLAVE EXTRANJERA en la orderstabla, estableciendo así su relación.
{kind=link}
Nicolás Raúl
Mawg dice que reincorpore a Monica
kenji kina
kenji kina
Nicolás Raúl
kenji kina